
Pricing & Monetization
Lago vs Stripe Billing: Feature Comparison, Pricing, and Open-Source Advantages
Anh-Tho Chuong • 4 min read
Oct 17, 2023
/10 min read
The founder of Cal.com had some choice of words for Stripe:
the data you get from @stripe via API is so fucking messy
its incredibly hard to replicate something as easy as MRR
why don't you give me some data endpoints that just return:
month | MRR
its ridiculous—Peer Richelsen (@peer_rich) September 11, 2023
Not very kind words. But unfortunately, he’s right. Calculating MRR using Stripe’s out-of-the-box API is very difficult. This might come as a surprise to many because Stripe does provide a nifty embedded dashboard in its admin portal that includes MRR amongst other core metrics.
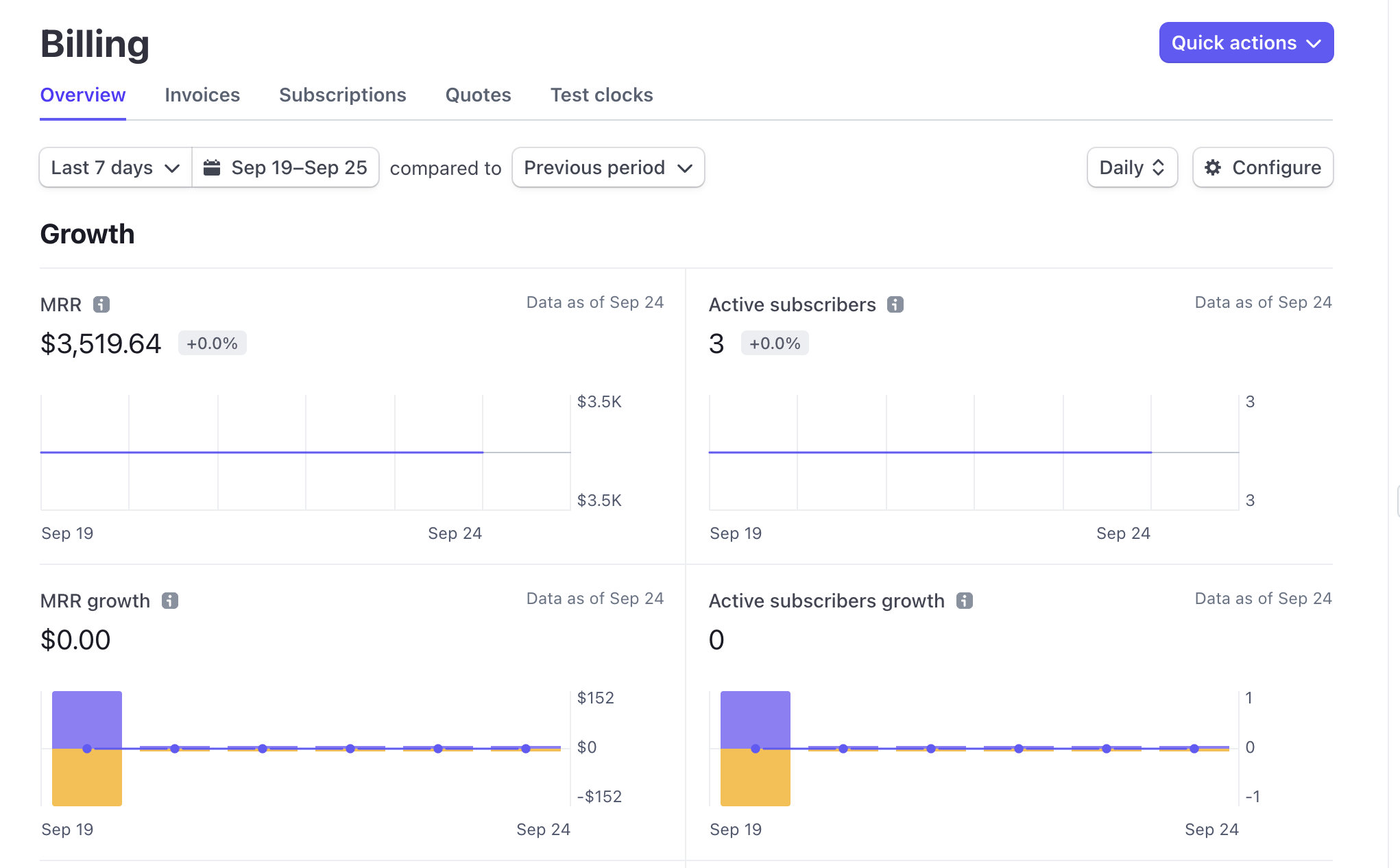
To a founder of a seed stage startup, this dashboard is both helpful and likely sufficient. But as companies grow, they want to do more with their data. And Stripe doesn’t have an API route that’s equivalent to <text-code>/getMRR<text-code> or something similar. Without serious legwork, getting statistics into your own warehouse or database using Stripe’s main API is tough.
This isn’t a matter of poor engineering. Stripe has one of the best engineering (and design) teams in the world. It’s just profit-maximizing strategy. Stripe keeps its API pretty barebones, expecting customers to purchase Stripe Sigma (fancy SQL editor) or Stripe Data Pipeline (in-house ETL tool) to better access data. Both of these tools add a cost per transaction, which is a little ridiculous given that Stripe’s base rate is higher than competitors, PayPal and Square.
If you are locked into Stripe, you still have options. Some, as aforementioned, are internal Stripe add-ons. Others are third-party tools. And, to spoil the surprise, they all come with a cost.
Stripe Data Pipeline is a limited ETL product that syncs Stripe data with a Snowflake or Amazon Redshift warehouse (presumably, they are building more integrations, but Stripe only supports those two presently). Advertised customers of Stripe Data Pipeline include Doordash, Slack, Zoom, and Hubspot.
While Stripe will definitely cut a volume deal to larger players, its base cost is $0.03 or €0.025 per transaction. Transaction, in this case, includes whenever a user was charged, an authorization was submitted, or a payment was requested. (While this post is mostly critical of Stripe, it’s worth acknowledging that Stripe includes provisions to not double charge customers for the same transaction, e.g. if an authorization is captured, it counts as one transaction, not two).
These Stripe extra fees can sound small. What’s a few cents, here and there? Well, it’s not a few cents. Sure, Stripe Data Pipeline is a great deal for customers where the median charge is $200-300, as the per-transaction fee reduces to a rounding error. But for companies with lots of smaller transactions (e.g. DoorDash or Lime), these charges are hardly trivial. They won’t overshadow Stripe’s core rake, but they add-up. There were 816 million DoorDash orders in 2020; even if Stripe cut DoorDash a hefty 50% discount, that’s $10,200,000 annually. For $10M/year, I’m willing to bet you could build an entire billing company.
Stripe Sigma isn’t exactly a replacement for exporting data (it supports CSV exports of reports, but that’s hardly data warehouse material). However, it does address some of the needs that a data warehouse might be attempting to solve, so it’s a worthy mention. For instance, you can calculate MRR (within reason) using Stripe Sigma.
Stripe Sigma is advertised as a collaborative, data-querying product that looks like a PopSQL or Basedash. Teams can collaborate on SQL queries and filter / group data like they would when accessing a Postgres database. Data can be exported as a CSV or shared via a platform link.
And, for what it’s worth, Stripe Sigma is a helpful solution for a very specific type of company. A company where a data warehouse is overkill, transaction count is manageable, but data is abundant requiring analysis. I can name twenty people heading up mid-sized companies that’ll likely benefit from Stripe Sigma.
But just like Stripe Data Pipeline, Stripe Sigma is expensive when you add up the numbers. Alongside a base fee ($10/mo - $100/mo for <50K transactions), Stripe charges an additional $0.020/transaction/mo - $0.014/transaction/mo based on volume. If a DoorDash employee queried all of their transaction history using Stripe Sigma, DoorDash’s CFO might have a stroke.
When you hear “usage-based billing”, you might think of a classic developer tool that charges per API call or server hours. Realistically, many SaaS applications feature usage-based billing because of seats. Technically, seats are a metric of usage. They can go up and down on a month-by-month basis, and seat costs are typically prorated.
The thing is, seats aren’t usually a volatile thing. Most SaaS apps don’t see customers radically changing seats unless there was a fresh round of funding, a massive layoff, or some weird restructuring. They are a quasi-MRR unit. We call it usage-based MRR, even if that sounds like an oxymoron.
Stripe makes usage-based metrics impossible. We’re not arguing that they should be easy; accounting for various nuances of different billing metrics is difficult. But Stripe is entirely based on a subscription-based model. It’s not designed to be personalizable to businesses with various growth metrics. This creates a mess when analyzing data, even raw data exported from Stripe.
This is my favorite part. I’m always humored when massive companies could be built due to some design flaw of another product. Salesforce has a ton of these, and Stripe is no exception. ChartMogul (39M / yr in revenue) and ProfitWell (acquired for $200M) strictly exist due to Stripe’s limitations.
With both, you can generate reports or consolidate exports into data warehouses. They won’t account for everything (e.g. usage-based MRR), but they are a level-up from Stripe’s raw API.
This one is a bit extraneous, but Pigment is a neat tool designed for FP&A teams (Financial Planning and Analysis). Basically the folks that evaluate how to save money and make more money.
Today, Pigment does not integrate with Stripe, but it’s high-up on their roadmap. If I was to make a wild guess, they’ll announce an integration soon given how big of a space this is. With Pigment, teams could answer big-picture growth-based financial questions and build helpful dashboards. But, as you might gather, it’s for very large companies and isn’t priced for your average Series ABC startup.
Instead of using Stripe’s native ETL tool, Stripe Data Pipeline, you can use a third-party ETL / ELT tool to pull Stripe’s data into a warehouse. This is a good strategy for teams that already use an ETL / ELT tool for other purposes. Common examples of these are Airbyte, Fivetran, and Stitch. (The difference between ELT and ETL is where and how the data is transformed, but the general I/O is the same).
Of course, pulling data into Redshift or Snowflake doesn’t automatically solve your problem. You still need to calculate MRR. This is non-trivial. If we were to return to our Cal.com friend, you can witness the frustration with his Benjamin Franklin offer:
i have these tables, first one to give me a working SQL query i'll give $100 lol pic.twitter.com/5W2onuWjeZ— Peer Richelsen (@peer_rich) September 11, 2023
Full disclosure, Lago is an open source billing solution. But the reason we’re so passionate about this subject is the same reason we built the Lago framework.
By leveraging open source billing solutions, you’ll retain full ownership over your billing infrastructure. Of course, you can also build your own billing engine, and if you have the engineering bandwidth to do that, more power to you. But, given that billing is very hard with lots of edge cases, many companies turn to external billing providers; all we’re saying is use an open-source one.
Take Lago, for instance. If you use our Docker distribution, you’ll immediately get a leg-up on Stripe users:
Of course, as developers of commercial open source software (COSS), we have our biases. But no one can deny, even Stripe engineers, that getting instant access to your financial data in Postgres—sweet, open-source Postgres—is very handy. (We use Postgres, if that wasn’t obvious). The table is broken into simple tables like invoices, events, and fees.
Because you own your data, you can easily ingest it into an analytics tool (like open-source Metabase) to build your own dashboards.
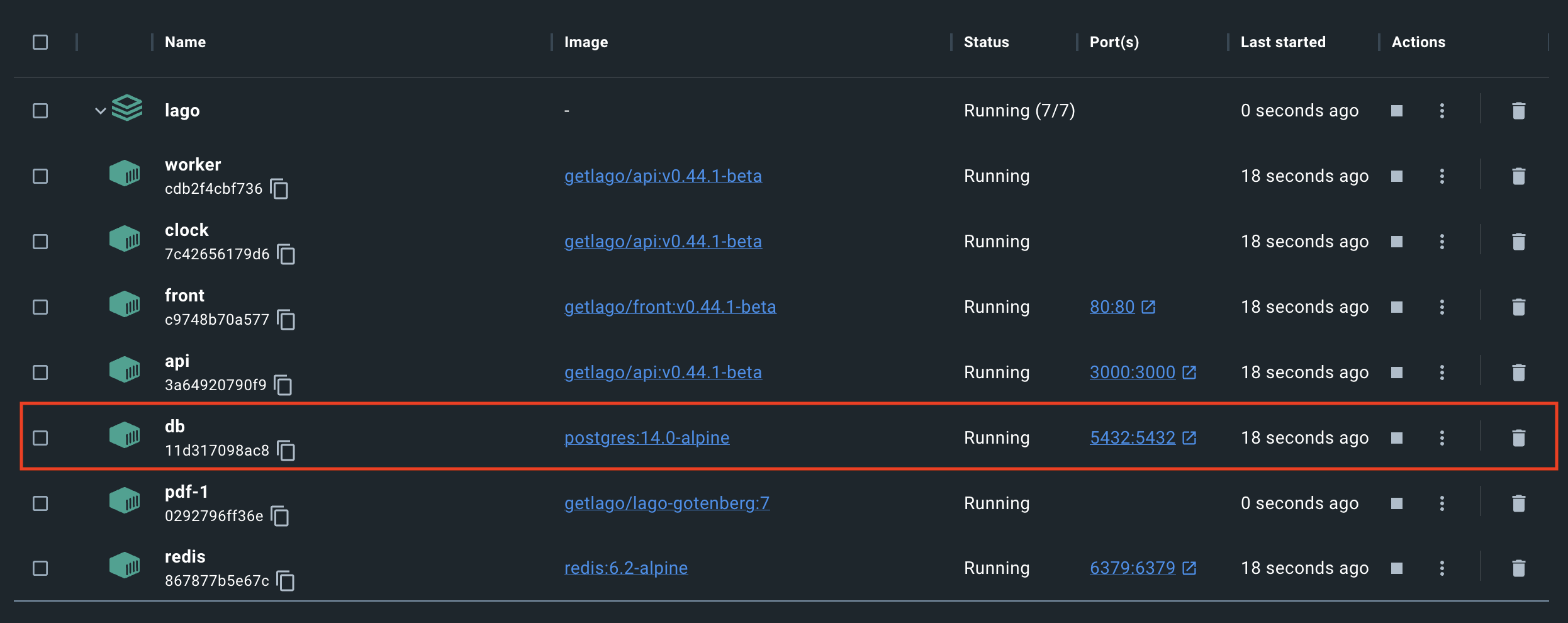
Or, if you use one of the many closed-source BI tools, that works too. The point is that the data is yours, and the PSQL queries are your oyster.
If you are serious about considering an open source library like Lago, it’s worth flipping through some basic revenue queries. To be clear, these are only basic queries for the sake of example—you can go a lot deeper with more advanced retention data.
If you want to calculate the total revenue with Lago, you will need to use the invoices table. In this table, there’s a simple trinity:
Accordingly, a sample query for calculating total revenue looks like:

If you want to break that data into month-by-month buckets, you can truncate it using <text-code>COALESCE<text-code> and a simple <text-code>GROUP BY<text-code> / <text-code>ORDER BY<text-code> pair.

This results in a table that looks like this (please pardon my literal French):
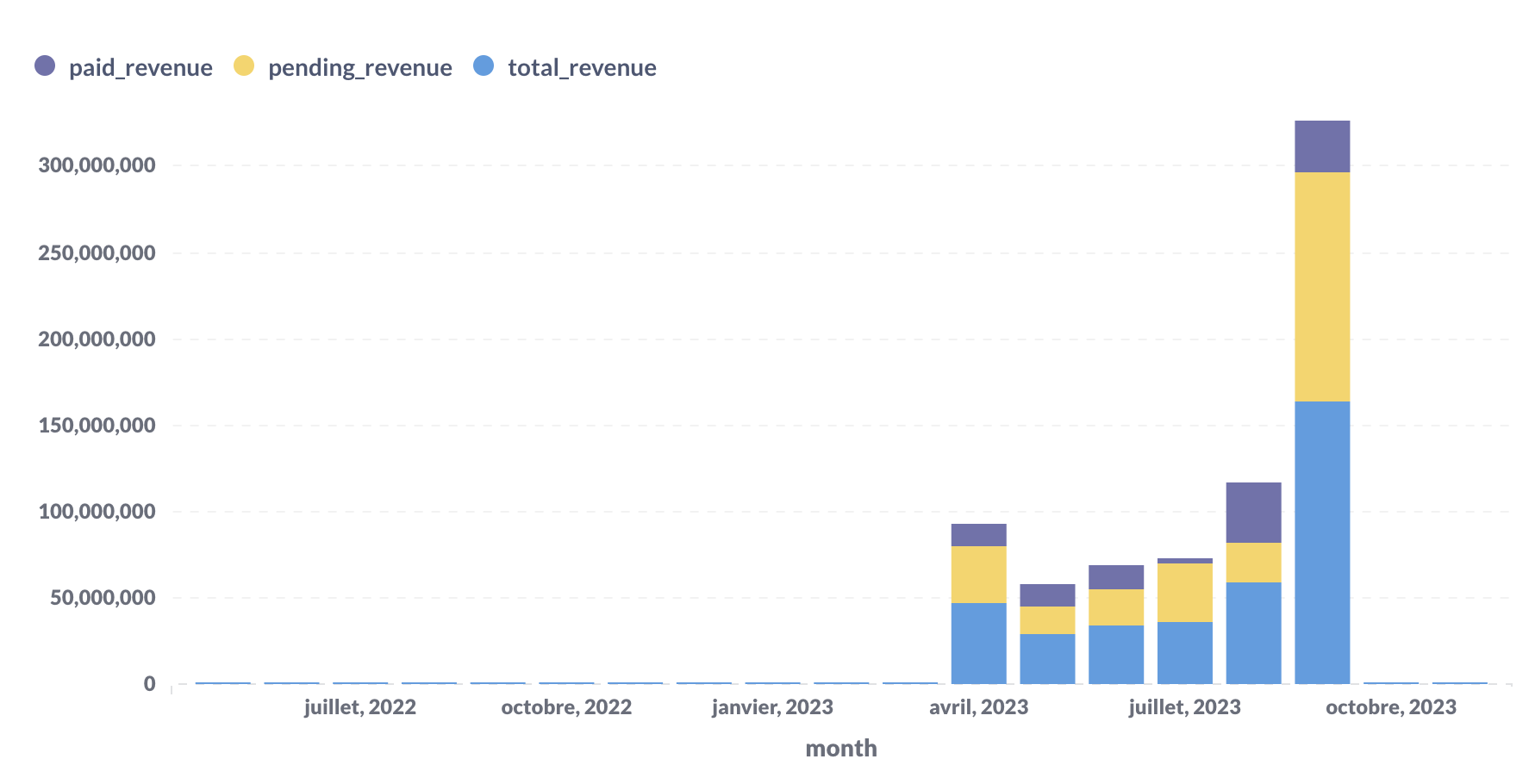
Some notes on the table:
MRR is tracking and calculating revenue from recurring <text-code>subscription<text-code> fees. To effectively calculate MRR, you'll need to fetch data from the <text-code>fees<text-code> table as part of the input data, and remove anything related to usage (called <text-code>charge<text-code> in Lago) and <text-code>add-ons<text-code> (created by one-time invoices).
The query amounts to:

A likewise query for calculating ARR looks like:

Some notes here:
Regardless, even with some additional contingencies, calculating MRR or ARR using an open source solution is really easy.
Since Lago operates first as a usage-based billing solution, optimizing the calculation of usage is crucial. You can refer to this as "Usage MRR," which may not follow a consistent usage pattern (i.e. not necessarily recurring) and can exhibit fluctuations between months.
To calculate Usage MRR, you will need to fetch data from the <text-code>fees<text-code> table as part of the input data, and add only fees related to usage (called <text-code>charge<text-code> in Lago). Some of the charges can be <text-code>recurring<text-code> (more predictable), and others can be <text-code>metered<text-code> (less predictable).

Unfortunately, as closed-source companies grow, they tend to forgo basic features in favor of incentivizing upgrades. This is exactly the case with Stripe. Stripe wants customers to purchase Stripe Data Pipeline or Stripe Sigma to increase their per transaction revenue per customer. In certain cases, these tools are great and affordable, but for many, it’s very expensive.
Worse, Stripe’s structure makes calculating recurring revenue very, very difficult whenever organizations leverage a usage-based billing model. And that includes everyday SaaS apps that bill on a per-seat basis. There are tools to solve this (such as ProfitWell and Pigment), but they are either expensive, built for larger companies, or both.
The most surefire approach to conquer your billing woes is to build billing in-house or leverage an open source framework. We’re obviously biased towards the latter (particularly our open source framework), but the point stands that companies shouldn’t let their financial data be held hostage to the land and expand goals of Stripe’s sales team.


