
Engineering
REST API Design Guide for Billing: Best Practices 2026
Anh-Tho Chuong • 16 min read
Feb 26
/7 min read
Most AI features in SaaS are glorified search bars — a chatbot that reads your docs and rephrases the answer. We didn't want to build that. We wanted to build agents that can apply discounts, void invoices, and retry payments — which surfaces open-source AI development challenges of its own. That meant solving problems most companies never face, and it's why we shipped our first AI features in late 2025, long after the first wave of RAG chatbots. Here's what our category taught us about when “easy” is actually hard.
I've seen enough features rushed to market to jump on a trend (remember NFTs?) and decided we wouldn't fall into that trap.
Just for context, we split our AI features into three distinct assistants, two of which are currently live.
Many in-product chatbots aren't very useful. They do the same thing as GPT/Claude with web search (read documentation and answer the question), but without the UX.
This is why I asked myself a question more product leaders should ask: Do we need to be building this? Or can users get the same value elsewhere?
This is especially important because you don't just build once and let it run. Factoring in the opportunity cost, ongoing maintenance and token costs can make building the wrong feature much more expensive than wasted engineering time.
But Lago has proprietary data: Usage events, revenue, customers, entities… the kind of stuff you'd be very worried if ChatGPT found with web search. We realized our customers couldn't automate billing workflows with AI if we didn't build it.
But for this to become useful, we wanted to build true agents, not just a chatbot that gets you hopefully-correct data you could've found in two clicks.
This made a big difference because building an agent that operates APIs is harder than building a chatbot, especially in billing. It requires permission systems, confirmation flows, audit logs and safeguards.
Our product is the financial backbone of our customers. It directly touches accounting, compliance and security, which means we can't operate the way many startups do: only fix edge cases once someone complains, ignore known bugs if they don't happen often enough.
We need to get things just right, not directionally correct. This extends to our AI agents. You don't want a billing agent accidentally refunding your biggest customer.
This is why we waited:
Here's why it was so hard:
When people say AI chat is easy to build, they're talking about systems like this: A generic document chatbot.
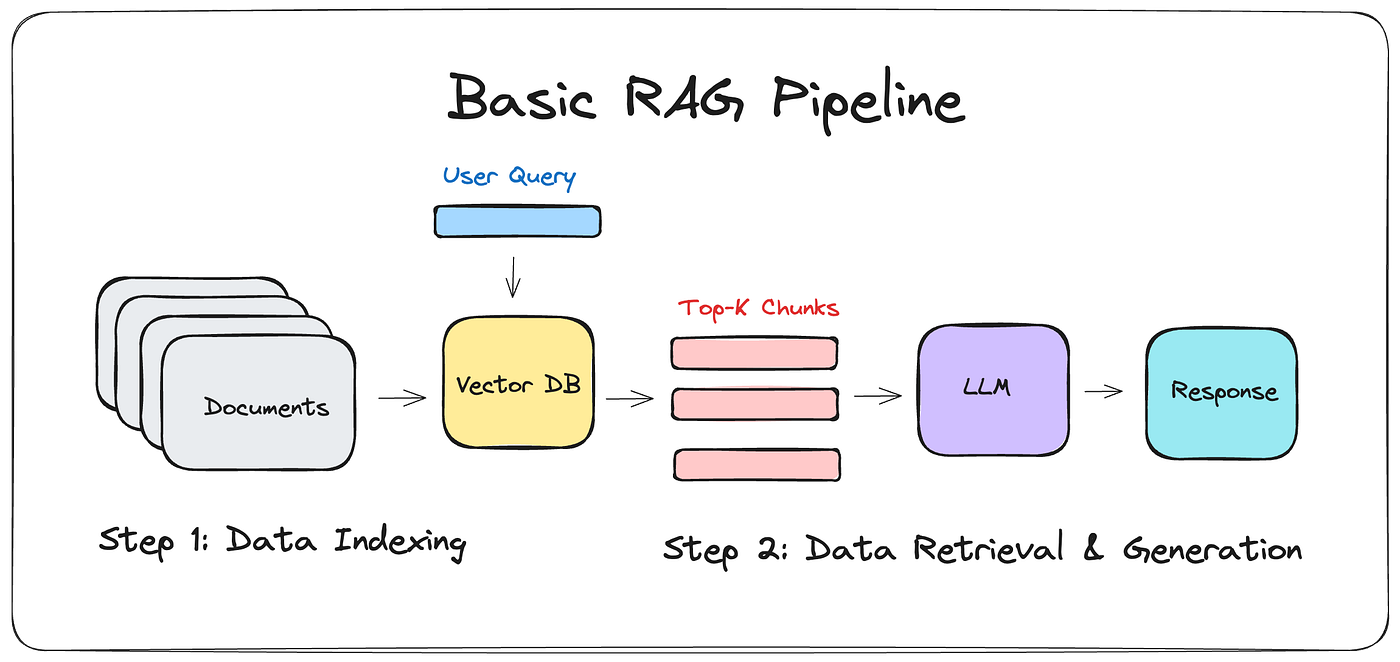
It extracts data relevant to the prompt and uses it to enrich the response. But this isn't what we built.
A chatbot is one layer: retrieve context, generate response. An agent that safely operates billing APIs requires three — and each layer exists because billing imposes constraints most AI products never deal with:
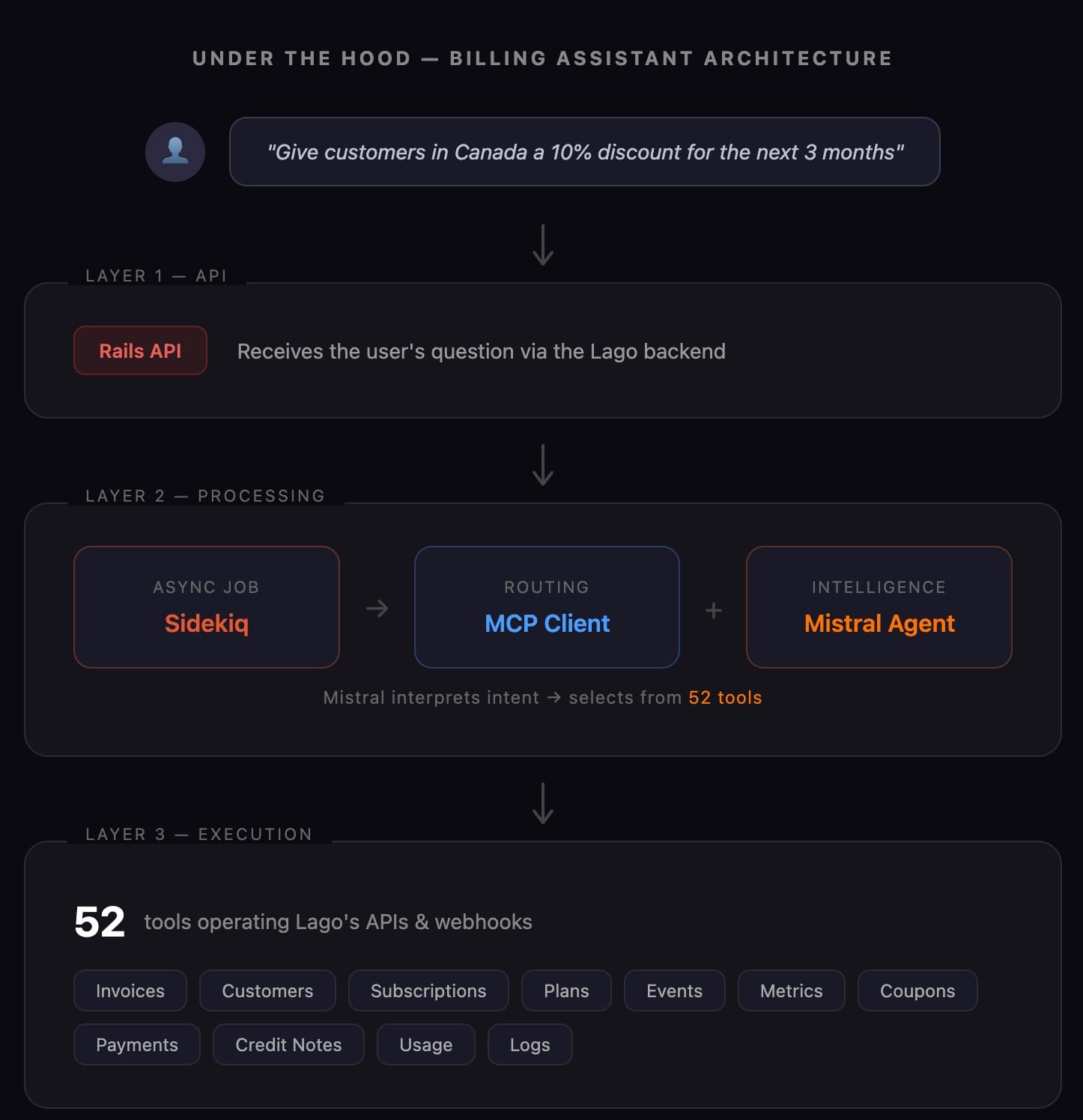
This is where (as you can tell) things got challenging. We had to:
And these are just the obvious things! Add to this the fact that everything is higher-stakes in billing.
For example, we needed to ensure the agents respected RBAC (role-based access control). You don't want your finance intern with "view only" access handing out discounts via chat. So our AI agents need to check permissions before every action. We also needed to ensure customers who used multiple entities got the correct results. There were a variety of these “little” things we had to get right.
But the biggest one was AI's biggest issue:
In most products, an AI hallucination is an inconvenience. In billing, it's a financial incident that harms trust and loses money. An agent that can void invoices, retry payments and apply discounts needs to get it right.

That's why we treat hallucination prevention as a system, not a prompt trick. Our approach has three layers: Constrain, Confirm, Exclude.
Constrain. Our Mistral agent operates under a detailed system prompt that constrains it to only use tools we've explicitly defined. It can't try, adapt and retry the API an OpenClaw instance might. This means it'll require slightly more user hand-holding, but also minimizes catastrophic results.
Confirm. We built guardrails before any consequential operation (create, update, delete, void, retry, refresh). In this, the agent must show the user a preview of exactly what it's about to do and wait for an explicit "yes." There's no “always allow” and you can't turn this off.
Exclude. We've also intentionally not built some tools. Organization management, API key settings, webhook setup and similar things can only be done manually.
The prompt also went through many, many iterations. We ran thousands of queries to stress-test it and find gaps. Some versions were too permissive (allowed things they shouldn't) or too long (ran out of context too quickly).
One of our biggest learnings from this is that even though AI is extremely powerful, you might not want to enable users to do whatever they want to do.
Imagine a product leader asks "what if we raised all prices by 20%?" If they're talking to the pricing assistant, they get strategic advice. If they're talking to a general-purpose agent with billing access, it might interpret this as an instruction to raise prices and execute the change.
This is why we built three separate AI assistants, not one.
Lago is cross-functional. It's used by engineers, product/growth, finance and ops people. Depending on who uses it, the output they want is different. Finance wants data, or to find a specific invoice. Product/growth cares more about shipping their new pricing experiment quickly.
This is why selecting the right assistant already influences the outputs.

By separating assistants, we create guardrails. The billing assistant can execute actions but only within billing. The finance assistant can query but can't modify. The pricing assistant only advises.
It's easy to talk about what went well and how we solved things, but a lot went wrong. Here are a few.
The initial motivation wasn't a customer request, so scoping was hard. Billing is infrastructure that's often bought with a checklist. Customers evaluate billing systems in large part based on the exact features you support. That means many features we build directly come from customers/prospects which means we already know the spec.
Because we didn't start from a specific workflow, the scope kept expanding. We began with a handful of invoice tools, then kept adding. Today we have 52 tools. That's a lot.
Every tool you add makes the agent harder to control. At 10 tools, you're managing complexity. At 52, you're building a permission system inside a permission system — each tool needs its own guardrails, confirmation flows, and edge case handling.
Looking back, I'd start working with customers and see what workflows take the longest time, build tools for those and soft-launch it to those design partners.
Prompt engineering was its own project. Since our team is very engineer-driven, we expected the technical part to be the most difficult. But writing the system prompt was hard. Early versions had security gaps where the agent would sometimes execute actions without waiting for confirmation. Other versions were so detailed they burned through the context window before the conversation got anywhere useful.
These mistakes cost us weeks of engineering time and forced us to rethink assumptions we'd been carrying since day one. I'm sharing them because the sanitized version — “we planned carefully and it worked” — wouldn't be useful to anyone actually building this.
If you're adding AI agents to infrastructure software — billing, payments, security, anything where mistakes have real financial consequences — here's what we learned:
